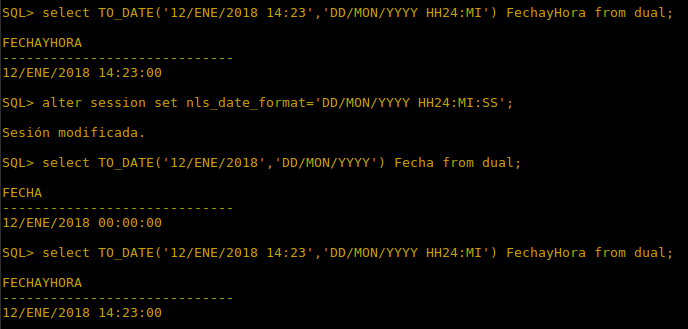
Elementos de la comunicación con un servidor Oracle
Para comunicar con el servidor de bases de datos, Oracle Database proporciona un sistema de al menos dos capas. Lo que implica a un cliente y a un servidor, los cuales utilizar alguna red de computadoras para conectar. Sin embargo es muy habitual que entre la capa del cliente y la del servidor haya que atravesar otra capa, formando un modelo de tres capas (según lo visto en el capítulo anterior). La
Ilustración 12 resalta los elementos más importantes en la comunicación cliente/servidor de Oracle:
La comunicación entre el cliente y el servidor se realiza a través de dos procesos:
- Proceso de usuario. Software que se ejecuta en el lado del cliente y se encarga de recoger las instrucciones lanzadas por el usuario y enviarlas al servidor.
- Proceso servidor. Software que se ejecuta en el servidor de bases de datos y que se encarga de procesar el código lanzado por el usuario.
Normalmente, hay un proceso servidor para cada usuario que conecte con la base de datos. Es decir, si hay diez conexiones, habrá diez procesos de usuario y diez procesos servidores.
Oracle, no obstante, proporciona un modo de trabajo llamado servidor compartido, en el que un mismo proceso servidor atiende a varios procesos de usuario. La razón es ahorrar memoria, aunque no sea tan eficiente como el modo dedicado.
[2.1.2]sesión y conexión
Hay dos elementos en la comunicación cliente/servidor que conviene diferenciar:
- Conexión. Mecanismo de comunicación entre el lado del cliente y el lado del servidor. A los extremos de esa comunicación se encuentran los procesos de usuario y de servidor.
- Sesión. Abarca la comunicación desde el mismo cliente hasta llegar a la base de datos. Una sesión requiere autentificar al usuario y otorgarle los recursos necesarios para una correcta comunicación. La sesión finaliza cuando el usuario abandona la aplicación de usuario o bien cuando desconecta. Un mismo usuario puede establecer varias sesiones (normalmente).
Es posible incluso que a través de la misma conexión se cree más de una sesión. Esa es la diferencia clave. La sesión hace referencia a datos que tienen que ver con el usuario y contraseña del sistema Oracle.
Los datos de la sesión se almacenan en el servidor. Los administradores pueden indagar sobre las sesiones actuales a través de la vista V$SESSION.
[2.1.3]modos de servidor dedicado y compartido

En principio, la forma de trabajar de Oracle Database es la que se conoce como modo de servidor dedicado. En ella por cada proceso servidor atiende a un único proceso de usuario. Dicho de otro modo, hay tantos procesos servidores como procesos de usuario.
Sin embargo existe la posibilidad de trabajar en modo de servidor compartido. En este caso cada proceso servidor atiende a varios procesos de usuario. Uno, o más, procesos, llamados dispatchers (repartidores), se encargan de asignar a cada proceso de usuario el proceso servidor adecuado.
En este modo se ahorra memoria, ya que la memoria de usuarios se almacena en la zona global compartida (llamada SGA).
[2.1.4]establecimiento de conexión
La conexión típica a Oracle comienza con una petición de acceso desde el lado del cliente.
Un proceso conocido como Listener, consigue “escuchar” dicha petición. El Listener es uno de los elementos fundamentales de Oracle Database. Su labor es gestionar el tráfico de las peticiones del cliente.
Una vez el Listener detecta la nueva petición, se establece conexión y comenzarán a comunicarse el proceso de usuario con su proceso servidor correspondiente.
El Listener se mantiene escuchando la comunicación (observar
Ilustración 15).
[2.2] funcionamiento de la instancia de Oracle
[2.2.1]arquitectura general de Oracle Database
Un servidor Oracle Database es el conjunto formado por estos dos elementos:
- La instancia de Oracle. Formada por el conjunto de procesos y las estructuras de datos en memoria que requiere el servidor cuando está en funcionamiento.
- Archivos de la base de datos. Los archivos en disco que almacenan de forma permanente la información de la base de datos. La base de datos en sí, la forman los archivos de datos, los de control y los Redo Log.
Un servidor de Oracle puede poseer más de una instancia, pero en general en estos apuntes trabajaremos bajo la hipótesis de tener un sistema de instancia simple. Las instancias múltiples se dan en sistemas distribuidos, en los que es posible disponer de más de una instancia (alojada en diferentes servidores) para la misma base de datos.
La
Ilustración 15 resume la arquitectura de Oracle. En ese diagrama las elipses representan procesos, los rectángulos son almacenes de datos en memoria RAM y los cilindros, archivos en disco.
[2.3] estructuras en memoria de la instancia de Oracle
[2.3.1]elementos de la memoria
Ilustración 16. Elementos de la memoria de Oracle. Se resaltan los principales componentes internos así como la comunicación entre el proceso cliente y el proceso servidor y su relación con la PGA y la SGA.
Como ya se ha comentado, una instancia está compuesta por las estructuras de memoria en las que se graban datos y por los procesos que dan servicio a la base de datos.
La
Ilustración 16 muestra el detalle de los componentes de la instancia. Cada proceso servidor (si el modo de trabajo es dedicado) atienden cada uno a un usuario.
Los datos en la instancia poseen dos grandes estructuras de almacenamiento:
- SGA (Server Global Area). Zona de la memoria en la que se guardan los datos globales de la instancia. Esos datos son los que comparten todos los procesos servidores, por lo que la mayoría de sus componentes son memorias de tipo caché. Muchas de sus áreas llevan el nombre de Pool. término inglés que, en este contexto, puede traducirse como fondo. En el sentido de un espacio en el que se reservan activos.
- PGA (Program Global Area). Zona de la memoria en la que se guardan los datos referentes a un proceso servidor concreto. Si el modo de trabajo es dedicado, si hay 5 conexiones habrá 5 procesos servidores y, por lo tanto, 5 PGAs. Al conjunto de todas las PGAs en uso, en un momento dado, se le llama instancia PGA. El tamaño de la instancia PGA se puede calibrar dentro de las opciones de configuración.
Pasamos, a continuación, a detallar los elementos de la instancia de Oracle. Inicialmente empezaremos por los elementos de la memoria y después detallaremos los principales procesos.
[2.3.2]componentes de la PGA
Como se ha comentado, la PGA contiene datos necesarios e independientes para cada proceso servidor. La información que contiene permite acelerar el proceso de las instrucciones SQL del clienteLa PGA se divide en dos zonas:
- Espacio de pila. Este espacio siempre (aun en modo compartido de servidor) se guarda fuera de la SGA. Es decir, se mantiene en la PGA siempre.
- UGA (User Global Area). Es el área global de usuario. En modo de servidor compartido este área puede pasar a la SGA (a la zona común de memoria). Este área se compone de los siguientes elementos:
- Área de trabajo SQL. Para el proceso de las instrucciones SQL. A su vez se dividen en:
- Área de ordenación. Para acelerar la ejecución de las cláusulas ORDER BY o GROUP BY.
- Área hash. Para uniones de tipo hash entre tablas.
- Área de creación de bitmaps. Para crear índices de tipo bitmap.
- Área de fusión de bitmaps. Para resolver índices de tipo bitmap.
- Memoria de sesión. Con los datos de las variables de sesión y de control de la sesión de usuario.
- Área privada SQL. Contiene información sobre la instrucción SQL en curso. Es un almacenamiento que permite almacenar datos referidos al estado de ejecución de las consultas y otras instrucciones. Lo más significado de este área es el uso del cursor.
El cursor es una estructura dentro del área privada que permite volcar al proceso de usuario los datos de las consultas SQL. Si una consulta devuelve 2000 filas, el cursor se encarga de ir volcando poco a poco esos datos.
Para ello un puntero en el área de datos del usuario permite relacionar los datos que ve el usuario con los datos del área privada.

Como ya se ha comentado, en el caso de utilizar un modo de servidor compartido hay datos que pasan a la SGA. Concretamente, la UGA pasará a la SGA y las PGA de cada conexión almacenarán solo el espacio de pila.
[2.3.3]componentes de la SGA
Pool Compartido (Shared Pool)
Se trata de una zona de memoria utilizada para acelerar la ejecución de las instrucciones SQL y PL/SQL.
Su espacio se divide en:
- Caché de biblioteca (Library Cache). Almacena código ejecutable de SQL y PL/SQL. Siempre que se ejecuta una nueva instrucción (SQL o PL/SQL), se comprueba si la ejecución de la misma esta disponible en este área. Dentro de este caché tenemos:
- Área SQL compartida (Shared SQL area). Contiene el plan de ejecución de la instrucción y el árbol de análisis de la misma. De esta forma se ahorra memoria cuando se repiten las instrucciones. También los elementos PL/SQL son cacheados de esta forma.
- Área SQL privada. Normalmente los datos privados de los usuarios, referidos a información sobre su sesión, necesarios para que una instrucción se ejecute correctamente, se almacenan en la PGA (como se puede comprobar en el apartado anterior). Pero en el modo compartido de servidor, se almacena en la SGA, concretamente en la caché de biblioteca en una zona separada del área de SQL compartida.
- Caché de Diccionario de Datos (Data Dictionary Cache). Se la conoce también como caché de fila ya que sus datos se almacenan en forma de fila (en el resto de cachés se almacenan en forma de bloques). Contiene información para acelerar el acceso a los metadatos que utilizan las instrucciones (también en la Caché de Biblioteca se guarda información sobre metadatos).
- Caché de resultados (Results cache). Tanto para SQL como para
PL/SQL, almacena fragmentos de consultas SQL y PL/SQL para aprovecharlos en consultas posteriores. El parámetro de sistema RESULT_CACHE_MODE permite establecer si todas las consultas almacenarán fragmentos en caché o sólo las marcadas de forma específica.
- Área fija. Es una zona pequeña donde se almacenan los datos necesarios para la carga inicial de la SGA en memoria.

Caché de Búferes de Datos (Database Buffer Cache)
Está dividida en bloques (más adelante se explica lo que es un bloque de base de datos) y es la estructura (normalmente) que más ocupa en la SGA. Oracle Database intenta que la modificación de datos en el disco tarde lo menos posible. La estrategia principal es escribir lo menos posible en el disco.
Por ello cuando una instrucción provoca modificar datos, inicialmente esos datos se graban en esta caché. La grabación ocurre tras la confirmación de una transacción. Después, cada cierto tiempo, se grabarán todos de golpe en los ficheros de datos (concretamente cuando ocurra un checkpoint).
Los datos, aunque no estén grabados realmente en disco, serán ya permanentes y aparecerán en las consultas que se realicen sobre ellos, además esas consultas serán más rápidas al no acceder al disco. Esto último es la segunda idea, que los datos a los que se accede más a menudo, estén en memoria y no se necesite leerlos del disco.
Los búferes de la caché se asignan con un complejo algoritmo basado en LRU (Last Recently Used) que da prioridad a los búferes que se han utilizado más recientemente.
Cada búfer puede estar en uno de estos estados
- Sin uso (Unused). Son bloques que no se están utilizando actualmente, por lo que están libres para cualquier proceso que requiere almacenar datos en ellos.
- Limpios (Clean). Son búferes que se han utilizado, pero cuyos datos ya están grabados en disco. El siguiente checkpoint no necesitaría grabar estos datos, por lo que están disponibles si se requiere su reutilización.
- Sucios (Dirty). Contienen datos que no se han grabado en disco. Se deben de grabar en el disco en cuanto ocurra un checkpoint, de otro modo podríamos perder información.
Además, con respecto al acceso, los búferes pueden tener estas dos situaciones:
- Libres (Free o Unpinned). Ningún proceso le está utilizando.
- Pinned. Están siendo utilizados por un proceso, por lo que otra sesión no puede acceder a este búfer.
La lectura de búferes sigue este proceso:
[1]Si necesitamos un dato, se le busca en esta caché. Si se encuentra se entrega, siempre y cuando no esté ocupado por otro proceso (pinned).
[2]Si el dato requerido no se encuentra en el búfer, ocurre un fallo de caché. Este fallo implica leer los datos del disco y pasarlos a memoria (los búferes necesarios se marcarán como búferes limpios).
[3]En ambos casos, si la instrucción implica modificar los datos de ese búfer, se modifica y pasa a ser un búfer sucio.
[4]Cuando ocurre un checkpoint, el proceso DBWn, graba búferes sucios a disco (lo mismo si se detecta que quedan pocos búferes limpios o sin uso) y se marcan como búferes limpios.
Otro detalle de esta zona de la SGA es que los búferes se agrupan en fondos de almacenamiento (Pools). Estos fondos son:
- Pool por defecto. Es el de uso normal. Normalmente es el único, salvo que se especifique el uso de otros.
- Pool KEEP. Se utiliza para bloques de uso muy frecuente, pero que dentro del fondo por defecto podrían ser reutilizados continuamente si no disponemos de espacio suficiente.
- Pool RECYCLE. Se utiliza para bloques de uso muy poco frecuente. El uso de este pool previene de usar estos bloques en el pool por defecto.
- Pools nK. El tamaño de bloque es una cuestión importante en una base de datos (más adelante se especificara lo que es un bloque). Aunque la base de datos tiene un tamaño de bloque por defecto, en algunos tablespaces (elemento en el que se guardan los objetos, se describe más adelante), podríamos variar ese tamaño. Por ello podríamos tener otros cachés orientados a estos elementos de tamaño especial. En la Ilustración 19, como ejemplo, aparecen dos fondos de tamaño 2K y 4K.
Búfer de Redo Log
Se trata de un búfer circular. Se van utilizando los bloques y, cuando se han usado todos, se vuelven a reutilizar los primeros en caso necesario y así continuamente.
Su función es almacenar la información acerca de los últimos cambios (DML confirmados y DDL) realizados sobre la base de datos. Esta información se vuelca continuamente, mediante el proceso LGWR, a los archivos de datos.
Los Redo Log son necesarios para recuperar los datos que no han podido ser grabados definitivamente en disco (normalmente por ocurrir una situación de excepción antes de un CHECKPOINT).
Pool Grande (Large Pool)
Área opcional de la SGA que proporciona espacio para los datos necesarios para realizar operaciones que impliquen muchos datos:
- Backup y restauración, para copias de seguridad.
- Procesos de Entrada/Salida del servidor.
- Memoria libre. Para aliviar el trabajo de la instancia.
- Consultas en paralelo.
- Almacenamiento de la UGA. Normalmente la UGA se almacena en la PGA, pero en modo de servidor compartido se podría almacenar en este área.
- Cola de peticiones. Especialmente importante cuando el servidor recibe numerosas peticiones. No se almacenan bloques de datos en este caso.
- Cola de respuestas. Tampoco utiliza bloques, sino estructuras más apropiadas para las colas.
Esta área de memoria no ocupa bloques usando el algoritmo LRU (a diferencia del Pool Compartido y de la Caché de Búferes de Datos), sino que los bloques quedan asignados hasta que queden marcados, por el proceso que los utilizó, como libres para otros procesos.
Pool de Java
Sólo se usa para los programas que utilizan Java.
Pool de Streams
Lo usa sólo el componente Oracle Streams (utilizado para bases de datos distribuidas) y sirve para almacenar en búferes, datos manejados por dicho componente.
[2.4] procesos de la memoria de Oracle
[2.4.1]tipos de procesos
- Proceso de usuario.
- Procesos de bases de datos. Compuestos por:
- Proceso servidor.
- Procesos en segundo plano.
- Procesos de la aplicación. Son demonios (daemons), servicios residentes que se ejecutan de forma automática. El más conocido es el listener de red.
[2.4.2]tareas de los procesos servidores
Los procesos servidores atienden a los procesos de usuario. Sus labores fundamentales son:
- Analizar el código SQL o PL/SQL lanzado por el proceso de usuario
- Establecer el plan de ejecución de la consulta SQL lanzada por el usuario
- Leer los datos requeridos por ese código en la memoria SGA o en el disco (si no están en la SGA).
- Devolver los resultados al proceso de usuario o indicarle, si es el caso, el error producido.
[2.4.3]procesos en segundo plano
Los procesos en segundo plano se ejecutan al lanzar la instancia de Oracle y quedan residentes en memoria realizando diversas labores en el servidor. La vista V$DBPROCESS permite obtener información de los procesos en memoria.
A continuación se detallan las acciones de los principales procesos.
DBWn.
El proceso de escritura de base de datos (DataBase Writer Process) DaEscribe los bloques modificados del buffer de cache de la base de datos (dirty buffers) de la caché de búferes de datos de la SGA a los archivo de datos en disco. Eso no ocurre en todo momento, sino cuando se produce un evento de tipo checkpoint.
El hecho de que esto se haga solo cada cierto tiempo (el tiempo establecido para el checkpoint) se debe a que, de otro modo, el funcionamiento del servidor sería muy lento si se accediera más a menudo al disco.
La n en el nombre (DBWn) indica que no hay un solo proceso DBW, sino que puede haber hasta 20 dependiendo de la potencia del servidor (DBW0, DBW1, …). En un sistema con un solo procesador lo lógico es que haya solo uno. El parámetro de sistema DB_WRITER_PROCESSES se encarga de definir el número de procesos DBWn.
La escritura en disco de los bloques sucios ocurre si:
- Un proceso servidor necesita modificar datos en la caché de búferes de datos y no encuentra bloques libres o limpios.
- Hay un checkpoint o punto de control.
DBW escribe los búferes en disco en lotes, para ganar eficacia. Al grabar los datos, graba el número de secuencia de cambio (SCN) en el disco. Este número indica la transacción que se está grabando. Como en los Redo Log también se usa esa secuencia, los datos grabados en los Redo Log y en los ficheros de datos se pueden comparar y saber qué archivos están más al día (siempre estarán más actualizados los Red Log) y así, en caso de recuperación, determinar los SCN que faltan.
Como se ha dicho antes, se graban los datos cuando ocurre un checkpoint o cuando faltan bloques para asignar en la caché de búferes de datos. En realidad en ambos casos, diremos que ha ocurrido un checkpoint.
Hay dos formas de actuar de DBW, la diferencia está en el tipo de checkpoint que le llega. Hay dos tipos: checkpoint incremental y checkpoint total (cuando se habla de checkpoint a secas, nos estaremos refiriendo a este último).
La cuestión es que puede haber miles y miles de búferes ocupados para ser guardados en los archivos de datos, lo que supone que esa sea una tarea larga y, por lo tanto, peligrosa porque durante todo el tiempo de escritura, un error crítico podría dejar la base de datos corrupta y no funcionar.
Los checkpoints incrementales sólo escriben unos cuantos búferes sucio marcándolos como libres, así el tiempo de grabación es más rápido.
Sólo cuando llega el checkpoint de verdad, el total, se graban absolutamente todos los búferes sucios. Esto ocurre menos a menudo, por lo que el riesgo de que se corrompa el disco, es menor.
DBW actúa si ocurre una de estas circunstancias (las tres primeras se corresponden a un checkpoint incremental y solo la última es un checkpoint total):
[1]No hay búferes libres en el búfer de datos de la SGA para seguir almacenando información; es decir, la caché de datos está a tope de ocupación. Si esto ocurre, Oracle escribe unos cuantos bloques sucios en los archivos de datos para poder liberar la ocupación de la memoria y disponer de más búferes libres.
[2]Hay demasiados bloques sucios. En ese caso se escriben unos cuantos bloques sucios en disco para liberar espacio. Es un caso previo al anterior que se basa en una medida de ocupación preventiva para no esperar a que no haya búferes libres, que sería más dramático.
[3]Se cumplió el tiempo de tres segundos de espera. En una base de datos ocupada, este evento no se cumple jamás. Ocurre cuando el sistema está sin hacer nada durante tres segundos. En ese caso se escriben unos cuantos bloques sucios. Si la base de datos sigue desocupada los siguientes tres segundos, se escriben otros tantos bloques. Así poco a poco (mientras la base de datos siga desocupada) acabará volcando todos los búferes en disco.
[4]La aparición de un evento de checkpoint (lo que hemos denominado un checkpoint total). Esto provoca escribir absolutamente todos los bloques sucios. Es el momento de máximo trabajo en disco y, por lo tanto, el momento más crítico porque en un
checkpoint se pueden tener que grabar miles de datos. Por ello, Oracle inicialmente pone el parámetro que controla el tiempo de aparición de un checkpoint a cero (que es lo mismo que tiempo infinito).
LGWR
Proceso de escritura de logs (LoG WriteR Process). Proceso encargado de escribir en los archivos redo log. Escribe los datos del búfer de Redo Log (en la SGA) a los archivos Redo Log en disco. Lo hace cuando:
En el buffer redo log se almacena información sobre los cambios recientes acaecidos en la base de datos. Como los datos no se escriben inmediatamente en los archivos de datos, esta información es la vital para recuperar la base de datos en caso de problemas.
Las instrucciones DML están limitadas por la velocidad de este proceso al guardar los datos. Es decir, la velocidad en grabar los datos en una base de datos Oracle, viene determinada por la velocidad de LGWR.
En caso de gran actividad de instrucciones DML entre varias sesiones, LGWR puede realizar confirmaciones en grupo para minimizar el impacto de la escritura en disco.
CKPT
Proceso encargado de registrar la llegada de un checkpoint, momento en el que se graban búferes de datos en los archivos de datos. CKPT graba en los archivos de control la posición de checkpoint y el SCN correspondiente en los Red Log.
También graba en los archivos de datos (en la cabecera) para actualizarla con la información del punto de control y la información sobre el último SCN que se ha grabado.
Además comunica a DBW la necesidad de grabar los búferes sucios.
SMON
System Monitor. Proceso encargado de monitorizar el sistema. Sus principales labores son:
- Recuperar la instancia al iniciar.
- Limpiar segmentos temporales que ya no se usan.
- Recuperar los datos de las transacciones existentes en los Redo Log que no están grabadas en los archivos de datos durante el arranque de la instancia.
SMON puede ser invocado por otros procesos.
PMON
Process Monitor. Se encarga de gestionar el fallo en un proceso de usuario. Sus labores son:
- Comprobar el estado de los procesos servidores y distribuidores (dispatchers).
- Reiniciar procesos servidores y distribuidores que hayan fallado.
- Si falla un proceso de usuario
- Limpia la caché de búferes de datos
- Libera los recursos que se utilizaron para atender a ese proceso de usuario
RECO
Se usa solo en bases de datos distribuidas. Resuelve los fallos ocurridos en transacciones distribuidas. Cuando detecta fallos en una transacción que tiene diferentes datos en los distintos servidores, se encarga de resolver la situación.
MMON y MMNL
MMON es el proceso monitor de manejabilidad (manageability monitor process), encargado de realizar tareas relacionadas con el AWR, área de volcado de estadísticas de los servidores Oracle.
MMNL es el proceso ligero de monitorización de manejabilidad (manageability monitor lite process), encargado de escribir estadísticas desde el histórico de sesiones activas (ASH) en la SGA de Oracle a el disco.
Ambos son procesos necesarios para que la información estadística sobre la ejecución de Oracle esté al día.
ARCn.
Procesos de archivado (archiver processes), encargado de escribir los archivos redo log históricos. Estos archivos son copias de los archivos Red Log. Se usan para recuperar información o para devolver la base de datos a un estado anterior.
Solo funcionan en modo ARCHIVELOG de la base de datos.
La n indica que pueden ser varios procesos (ARC0, ARC1, etc.).
CJQ0 y Jnnn
Es el gestor de colas de trabajo (job queue processes). Los trabajos son tareas programadas por los usuarios que se pueden ejecutar varias veces.
Cada trabajo se asocia a un proceso Jnnn (por ejemplo J001).
El programador de tareas de Oracle puede invocar a CJQn cuando se necesitan ejecutar trabajos. Entonces CJQ0 lanza los procesos Jnnn de forma apropiada. Cuando finalizan los trabajos, CJQ0 se queda en estado de espera, hasta que se le vuelva a necesitar.
FBDA
El FlashBack Data Archiver Process, es el proceso encargado de grabar la información del área de Flashback. Esta área se usa para el caso de necesitar que la base de datos regrese a un estado anterior.
[2.5] estructuras de almacenamiento en disco
[2.5.1]introducción
Una base de datos Oracle necesita los siguientes archivos para grabar la información de la misma:
- Archivos de datos
- Archivos de control
- Archivos Red Log
Además posee (o puede poseer) estos otros archivos para que la ejecución sea correcta:
- Archivos de parámetros
- Archivo de contraseña
- Archivos de traza y alerta
- Archivos históricos (o archivados) Red Log
- Archivos de copia de seguridad
[2.5.2]archivos de datos
Son los archivos que almacenan los datos en sí de la base de datos. Graban la información de las tablas. Para optimizar su funcionamiento y su gestión, Oracle utiliza una estructura que relaciona la lógica de la base de datos, con la parte física.
Esta lógica interna de Oracle se describe a continuación.
estructuras lógicas de almacenamiento de Oracle
En realidad estas estructuras forman un esquema de la base de datos que se situarían conceptualmente entre el esquema interno y el físico de la base de datos.
Oracle llama a estas estructuras Logical Storage Structures, por lo que en español se suele traducir como estructuras lógicas de almacenamiento.
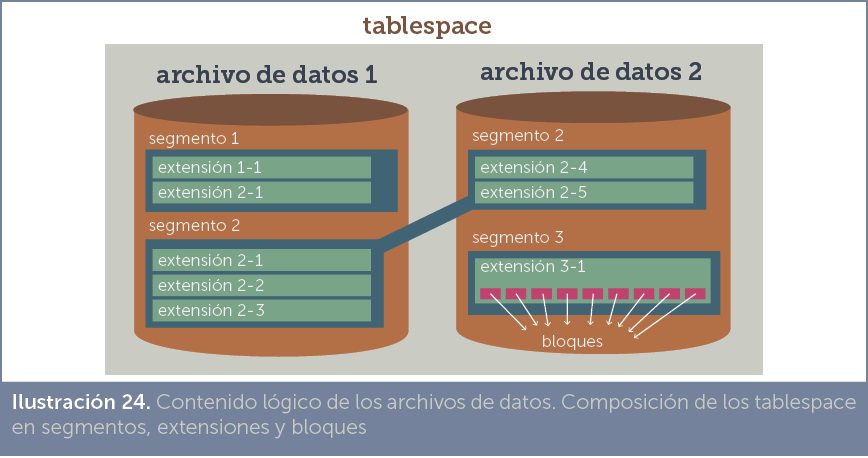
tablespaces
Los espacios de tabla o tablespaces, son una estructura lógica que, conceptualmente, se sitúa entre la lógica de la base de datos y las estructuras físicas que almacenarán los datos.
En la base de datos, se manejan objetos a nivel lógico (tablas, columnas, filas, vistas, índices,…). La información de esos objetos se tiene que almacenar en archivos de datos. Oracle crea los tablespaces como un elemento intermedio entre el nivel lógico y el nivel físico de la base de datos. Relaciona ambas ópticas para optimizar el funcionamiento del sistema.
Por defecto Oracle proporciona los siguientes espacios de tabla:
- USERS. Almacén por defecto en el que los diferentes usuarios de la base de datos almacenan sus objetos.
- SYSTEM. Para los objetos del sistema como el diccionario de datos
- SYSAUX. Para componentes adicionales de la base de datos como por ejemplo el repositorio del Enterprise Manager.
Naturalmente podemos crear otros tablespaces y asignarles los archivos de datos que deseemos.
Los tablespaces se dividen en segmentos, estos en extensiones y las extensiones en bloques.
Un tablespace puede abarcar más de un fichero de datos. Cada fichero, sin embargo, se asigna a solamente un tablespace.
segmentos
En cada tablespace existen segmentos, que están relacionados directamente con un objeto de la base de datos (una tabla, un índice,…). Hay tres tipos de segmentos:
- Segmentos de usuario. Almacenan los objetos de base de datoscreados por los usuarios. Por ejemplo:
- Segmentos de datos. Almacenan los datos de las tablas (incluidas las particionadas y las tablas en cluster, que son tipos de tablas avanzadas).
- Segmentos de índice. Almacenan los datos necesarios para la creación de índices.
- Segmentos de tipo LOB. Para almacenar los datos de tipos grandes de Oracle: CLOB y BLOB.
- Segmentos de anulación (undo). Almacena la información necesaria para revertir cambios realizados en los datos. El uso típico es la ejecución de la instrucción ROLLBACK (aunque hay muchos más).
- Segmentos temporales. Almacenan datos intermedios que Oracle necesita para completar consultas o instrucciones complejas que relacionan gran cantidad de datos (CREATE INDEX, SELECT DISTINCT, uniones, intersecciones, GROUP BY, etc.). Estos segmentos les crea y elimina Oracle automáticamente.
El mismo segmento puede estar presente en más de un archivo de datos (como en la
Ilustración 22 ocurre con el segmento que almacena la
tabla 3). Esta idea se usa para segmentos que almacenan datos de objetos con mucho contenido.
Para explicar, muchas veces se relaciona segmento con tabla. Pero realmente los segmentos almacenan otros objetos.
Por ejemplo esta instrucción (que crea una tabla no relaciona):
CREATE TABLE obras(titulo VARCHAR2(30));
|
Solo crearía un segmento para almacenar los datos de la tabla.
Sin embargo esta otra:
CREATE TABLE obras(
id_obra NUMBER PRIMARY KEY,
titulo VARCHAR2(30) UNIQUE,
texto CLOB
);
|
Creará, al menos, estos segmentos:
- Un segmento para los datos de la tabla obras.
- Otro para el índice de la clave principal.
- Otro para el índice de la restricción UNIQUE sobre la columna título.
- Otro para los datos CLOB.
- Otro, de tipo índice, para relacionar los datos CLOB con las filas de la tabla.
extensiones
Los segmentos se dividen en extensiones. Las extensiones son divisiones dentro del segmento que permiten asegurar que el sistema tiene reservado un conjunto de bloques contiguos en el disco. Es decir las extensiones evitan fragmentar en exceso los discos.
El funcionamiento es el siguiente: cuando hemos llenado un segmento, entonces se añade una extensión (el tamaño de las extensiones se puede calibrar) y eso significa que se amplia el segmento en el tamaño de dicha extensión. Es decir, se reserva ese espacio.
De esa forma los bloques siguientes (hasta llenar la extensión) que se añadan, tendremos la seguridad que irán contiguos en disco, disminuyendo su fragmentación.
Como es lógico, una extensión está asociada a sólo un archivo.
bloques de datos
Es el elemento de datos más pequeño distinguible por Oracle. Cada extensión consta de una serie de bloques. El tamaño de bloque se puede configurar por parte del DBA para optimizar el rendimiento.
El tamaño del bloque de datos debe cumplir que sea múltiplo del tamaño de bloque del disco del Sistema Operativo. Es decir si en un disco concreto, el Sistema Operativo tiene un tamaño de bloque de 16KB, sólo podremos asignar tamaños de bloque de 16 KB, 32 KB, 48 KB, 64 KB etc.
En el bloque de datos de Oracle, los datos se organizan en filas. Así se asegura que cada fila se almacena junta en el bloque de datos. Además en cada bloque se graba una cabecera con información general del bloque, de la tabla a la que pertenece y de las filas que almacena.
El espacio libre del bloque está en el interior, de modo que la cabecera y la información de las tablas crecen hacia el interior del bloque (véase
Ilustración 25).
posibilidades de gestión física de los archivos de datos
Oracle puede gestionar los archivos de datos de varias formas:
- Como archivos normales del Sistema Operativo. Es el caso más fácil y habitual, la gestión de los archivos se delega al sistema operativo. Lo que implica que se puedan copiar, borrar o examinar como cualquier otro archivo del sistema.
- Como particiones RAW. En ese caso todos los archivos de datos se integran en una estructura que, desde el sistema, parecería un archivo binario normal. La única finalidad es ocultar los archivos contenidos; en la práctica no se usa mucho.
- Gestionadas mediante el Automatic Storage Management (ASM). Se trata de un sistema de archivos propietario de Oracle que permite que la gestión de los archivos se realice desde una capa propia, en lugar de delegarla al Sistema Operativo.
Con ASM se consigue mayor rapidez y potencia ya que proporciona numerosas opciones de trabajo.
Su instalación es sencilla y sus puntos fuertes es el agrupar archivos y no unidades lógicas, permite ajustar parámetros de balanceo, redundancia o la integración eficiente en sistemas distribuidos.
Al ser un formato propio, requiere dar formato a unidades de disco (sea reales o virtuales) usando este sistema de archivos. ASM se basa en crear grupos de discos los cuales contienen uno o más discos ASM. Los grupos de discos se manejan como si fueran uno solo, para conseguir redundancia y balanceo de carga.
Los archivos de este sistema (archivos ASM) se corresponden con los archivos de datos de Oracle.

- Usando el Clustered File System (OCFS). Usado para instalaciones de servidores distribuidos en clúster (RAC) permite que los archivos se compartan entre varios servidores, haciendo que, en apariencia, su gestión sea como la de los archivos normales. Otra opción, mucho más utilizada, es ACFS que permite usar el sistema ASM en modo clúster.
[2.5.3]archivos Redo Log
Los Redo Log son dos o más archivos que sirven para almacenar las instrucciones DML que se van confirmando en la base de datos. No graban datos, sino la información necesaria para que esa instrucción se lleve a cabo.
Sirven para recuperar los datos en caso de desastre. Por ejemplo, si la base de datos ha confirmado una transacción correspondiente al número de secuencia de cambio número 9550, significará que esa secuencia estará grabada en los Red Log. Sin embargo, puede que los archivos de datos estén en la 9540. Lo cual significa que hay 10 secuencias en los Redo Log que no se han grabado en los ficheros de datos. Si ocurre un desastre en este instante y el sistema se cierra, dependemos de los Redo Log para recuperar esas secuencias.
Los redo log graban las instrucciones de transacciones confirmadas y los datos necesarios para volver a realizarlas. La información en los redo log se graba casi instantáneamente, por lo que siempre están más al día que los archivos de datos. Además, sirven como histórico de los cambios realizados en la base de datos. Lo que puede permitir retornar a la base de datos a un punto concreto.
Los ficheros Redo Log funcionan de forma circular. Cuando se llena uno, se produce un evento de tipo log switch. Si ocurre un log switch en el último archivo, se usa el primero, sobrescribiendo la información que tuviera.
El funcionamiento consiste en lo siguiente:
[1]Cuando el usuario realiza instrucciones DML o DDL, el proceso servidor graba en el Búfer Redo Log en la SGA, la información necesaria para que esa instrucción se vuelva a ejecutar, si fuera necesario.
[2]El proceso LGWR, cuando las instrucciones son definitivas (bien transacciones aceptadas o instrucciones DDL por ejemplo), copia los datos del búfer a los archivos redo log.
[3]Cuando llenamos el archivo redo log actual, se produce el evento log switch; entonces los siguientes datos pasan al siguiente archivo redo log. Con éste ocurrirá lo mismo y así sucesivamente con cada archivo del que dispongamos.
[4]En cada cambio de archivo, se genera un número de secuencia que va anotando la secuencia de redo log (lo que es lo mismo, el número de eventos log switch que han ocurrido), así podemos tener ahora el número de secuencia 12 indicando que hemos hecho 12 cambios de archivo (o sea, han ocurrido 12 eventos log switch).
[5]Cuando ya hemos ocupado todos los archivos, al terminar de llenar el último se produce el consiguiente log switch y como no hay más archivos disponibles, grabará los siguientes datos en el primer archivo sobrescribiendo los que ya existieran (y perdiendo esos datos). El número de secuencia seguirá incrementándose, no volverá a empezar de nuevo.
[6]Todo este proceso sigue continuamente
multiplexación, grupos de redo log
Los archivos redo log suelen constituir grupos. Esto significa que el primero archivo redo log, en realidad será un grupo de archivos. Cada grupo consta de varios archivos redo log clónicos correspondientes a las mismas secuencias (es decir tendremos varios archivos idénticos con los datos de una secuencia). La idea es que, si falla uno, tengamos otra copia disponible.
Cuando se graba un dato de tipo redo, se graba secuencialmente en todos los archivos miembros del grupo de forma multiplexada. Es decir, primero en uno, luego en otro y así hasta terminar el grupo.
Es tarea del administrador determinar la configuración de los redo log (número de grupos, número de archivos, ….). Así como decidir en qué discos se almacena cada archivo miembro de cada grupo. Lo ideal, es que los miembros de cada grupo estén en discos distintos para mayor seguridad.
Además hay que tener en cuenta que la grabación de la información en los redo log debe de ser lo más rápida posible; la grabación en disco (desde el búfer) es crítica, porque durante dicha grabación la sesión queda parada hasta terminar el volcado de datos. Por ello los discos donde se almacenen redo log deben de ser muy rápidos.
Por defecto la base de datos tendrá tres grupos, pero con un solo miembro cada uno (es la situación mostrada en la
Ilustración 27). Eso significa que no hay multiplexación y, por lo tanto, hay riesgo alto de perder un redo log.
[2.5.4]histórico de archivos redo log (archive redo log)
Se explicó en el apartado anterior que los archivos redo log tienen un comportamiento circular, es decir que cuando llegamos al último archivo, si se llena; entonces los siguientes datos pasan al primero, borrando la secuencia que estuviera grabada en él.
Esto no tiene que ser un problema ya que desde que se vuelve al primer archivo de la secuencia, los datos pueden estar ya grabados definitivamente en los archivos de datos mediante el proceso DBW.
Pero puede ocurrir que no sea así y esos datos no estuvieran grabados, por lo que en caso de caída del sistema les perdemos y eso sería una situación de desastre.
El registro histórico de archivo redo log (también llamado archivados redo log) evitan esta situación. Para ello la base de datos debe de estar en modo ARCHIVELOG (el modo contrario es el NOARCHIVELOG que es el habitual), si es así, entonces cada vez que ocurre un evento log switch (es decir cada vez que hay un cambio de secuencia), el proceso ARCn (la n significa que puede haber varios: ARC0, ARC1,…) graba una copia de la secuencia actual en el histórico.
Por ejemplo supongamos que tenemos tres grupos de archivos redo log y estamos en modo ARCHIVELOG:
[1]Inicialmente el proceso LGWR graba en la secuencia 1, suponemos que está secuencia se graba en el grupo 1 de archivos redo log (hay que recordar que un grupo de redo log puede estar formado por varios archivos clónicos redo log)
[2]Cuando la secuencia 1 se llena, pasamos a la secuencia 2 (se produce un log switch) y entonces el proceso ARC graba una copia de la secuencia 1 en el directorio de los históricos redo log (cuya ruta se puede configurar).
[3]Cuando la secuencia 2 se llena, entonces se copia esa secuencia en el histórico y pasaremos a la secuencia 3
[4]Cuando la secuencia 3 se llena, LGWR empezará a sobreescribir el grupo redo log que tenía la secuencia 1. El proceso ARC grabará una copia de la secuencia 3.
[5]Entonces se empezará a grabar los siguientes redo log en el grupo 1, sobrescribiendo la información anterior. Pero no pasa nada porque tenemos copia de todas las secuencias, incluida la 1.
Evidentemente el problema de esta forma de trabajar es el espacio que necesitamos. Además obligamos a Oracle a usar cada vez más los discos, con más procesos funcionando que requieren grabación en ellos. A cambio aseguramos que no perderemos información.
Incluso podemos multiplexar cada archivo del histórico para tener, no ya una copia, sino varias de cada secuencia, con lo que la seguridad es aún mayor.
[2.5.5]archivos de control
Se trata de archivos binarios y de tamaño pequeño que contienen la estructura de la base de datos, es decir metadatos. Este archivo también se puede multiplexar para aumentar la seguridad, con lo que puede haber varios. Lo normal es tener al menos dos, ya que es un recurso crítico.
Los archivos de control contienen:
- Nombre de la base de datos
- Fecha y hora de la creación de la base de datos
- Información sobre checkpoints y redo logs (secuencia actual de redo log, nº de checkpoint,…)
- Modo de archivado de la base de datos.
- Número de secuencia del redo log actual.
- Metadatos para labores de backup y recuperación de datos.
- Ubicación de los archivos de datos, redo log e históricos redo log
- Información sobre los tablespaces actuales
[2.5.6]otros archivos
archivos de parámetros
Contienen los parámetros generales de configuración de la base de datos. Los parámetros son el conjunto de una clave y un valor. Por ejemplo el parámetro con clave SGA_MAX_SIZE tendría como valor el tamaño máximo que podremos tener de SGA.
Hay dos tipos de archivos de parámetros:
- SPFILE. Se trata de un archivo de parámetros binario. El formato habitual del archivo de parámetros es este y sólo permite su edición modificando los parámetros desde Oracle.
- PFILE. Archivo de parámetros en forma de texto. La ventaja es que se puede editar su contenido incluso desde fuera de Oracle (directamente con un editor de texto).
Lo aconsejable es usar el formato SPFILE pero tener al menos una copia en formato PFILE.
Los parámetros sirven para cambiar y conocer la configuración de Oracle. Cada parámetro refleja un aspecto del funcionamiento de Oracle; modificándole, modificaremos el comportamiento de la instancia de Oracle.
archivos de contraseñas
Contienen la lista de contraseñas cifradas de los usuarios administradores. Son imprescindibles para que los usuarios de tipo DBA puedan conectar con la base de datos. En caso de pérdida no se podrá validar a los usuarios administradores, por lo que se conservación es crítica.
archivos de traza
Son archivos de texto que permiten establecer el seguimiento del funcionamiento de la base de datos. Gracias a ellos podremos saber las acciones llevadas a cabo por muchos procesos importantes de Oracle (como PMON y SMON por ejemplo) y así detectar problemas o cuellos de botella en el rendimiento.
El número y funcionamiento de cada archivo de traza se puede configurar para realizar el seguimiento deseada al funcionamiento de la base de datos..
archivo de alerta (alert log)
Es, en cierto modo, un archivo de traza pero que sirve para almacenar información sobre el funcionamiento de Oracle. Es el diario de Oracle, graba todas las cosas importantes acaecidas (cuando se inició la instancia, cada aparición de checkpoint, los eventos log switch,…).
Es un archivo de texto que se crea cuando la base de datos se lanza por primera vez y continuamente almacena lo que ocurre en ella.
archivos de copia de seguridad
Imprescindibles para la recuperación de la base de datos en caso de desastre.
archivos temporales
Son un tipo especial de archivo de datos que sirve para almacenar datos que proceden de operaciones que mueven tanta información que no cabe en la memoria y se necesita cachear en disco. Contienen datos intermedios necesarios para ejecutar algunas instrucciones. Cuando las instrucciones finalizan, se van borrando esos datos.
log de operaciones flashback
Oracle tiene la posibilidad de retornar la base de datos a un momento concreto de tiempo. Es un volver al pasado que permite anular una situación grave de pérdida de datos. Para ello se debe configurar Oracle con posibilidad de usar un área de flashback.
El archivo log para flashback contiene información necesaria para poder devolver la base de datos a un estado anterior en el tiempo. Es decir, son fundamentales para que una operación de tipo flashback pueda funcionar.
archivos DMP
Se utilizan para realizar operaciones de exportación e importación de datos. Contienen información independiente de la plataforma que permite realizar exitosamente la operación de exportación e importación. La información que contienen es binaria.
Fuente